
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- bulk_create
- 주니어개발자
- GraphQL
- cannot import name
- Spring
- SpringBoot
- Not Null constraint failed
- Java
- circular dependency
- 상속모델
- API문서화
- 2차원배열 정렬
- 토이프로젝트
- bean-validator
- DI
- 프로젝트설정
- Npoem
- IOC
- 함수형프로그래밍
- 객체비교
- resilience4j
- 쿼리셋합치기
- 컨트리뷰팅
- django
- n poem
- 좋은코드란
- circuitbreaker
- 운영체제
- 마이크로서비스패턴
- 일급함수
- Today
- Total
코딩 하는 가든
운영체제 - 프로세스와 스레드의 차이 본문
프로세스와 스레드의 차이
프로세스와 스레드의 차이에 대해서 기록합니다.
먼저 프로세스와 스레드의 차이를 알기 전에 프로세스가 무엇이고 어떻게 구성되어 있는지 알아보겠습니다.
프로세스란 프로그램의 실행 단위입니다. 프로그램은 우리가 알고 있듯이 우리가 원하는 기능을 수행해주는 소프트 웨어 입
니다. 프로그램은 여러 소스코드 등으로 구성되어 있고 프로그램을 실행시키면 정해진 약속에 따라 자기의 역할을 수행하게 됩니다.
프로그램의 소스코드를 읽고 계산하여 결과를 내려면 메모리 상에 코드를 올려놓고 cpu로 계산을 해야 할 것입니다. 이렇게 실행을 위해 메모리 상에 올라와 있는 프로그램을 프로세스라고 합니다.
[프로세스]
실행된 프로그램(프로세스)은 운영체제에 의해 메모리 공간을 할당받게 되는데,
하나의 프로세스는 Code, Data, Stack, Heap의 네 가지 영역으로 나뉜 메모리 공간을 할당 받게 됩니다.
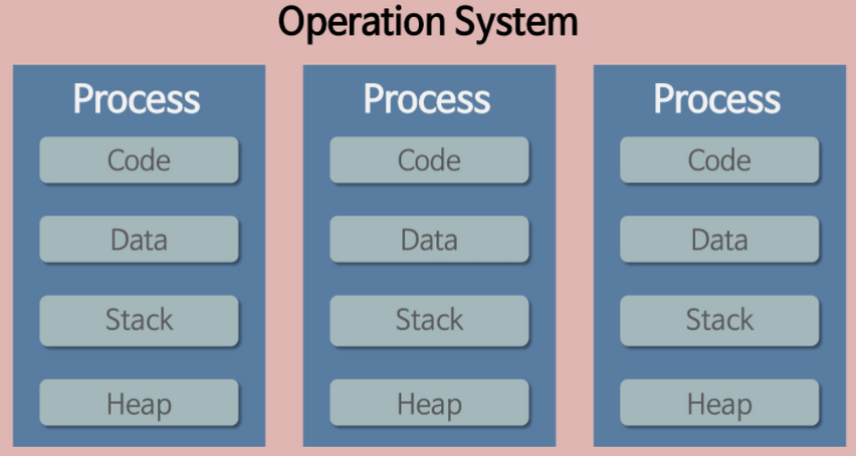
- Code : 실제로 실행할 코드를 저장하는 영역
- Data : 프로그램의 전역 변수, static변수, 초기화된 배열 등을 저장 하는 영역
- Stack : 지역 변수, 매개 변수, 함수의 return 주소 등을 저장 하는 영역
- Heap : 동적으로 할당된 메모리가 저장되는 영역 (new 클래스(), malloc() 등... )
위처럼 프로세스는 각자가 독립된 메모리 공간에 할당됩니다.
그렇다면 하나의 기능을 수행하다가 다른 기능을 수행하려면 다른 프로세스로 넘어가서 수행을 해야 합니다.
이렇게 되면 프로세스에서 다른 프로세스로 넘어가는 Context Switching 비용이 많이 발생하게 됩니다.
그렇기 때문에 '하나의 프로세스 안에서 실행의 단위를 나누어 컨텍스트 스위칭 비용을 줄이자!'
라는 뜻에서 탄생한 게 스레드입니다.
이렇게 실행되던 것을!

이렇게 실행합니다.

그림으로 보기에도 실행의 플로우가 프로세스에서 프로세스로 건너뛰는 것보다 하나의 프로세스 안에서 스레드 사이를 이동하는 것이 비용이 적어 보일 것입니다.
[스레드]
스레드는 위의 그림에서 보이듯 하나의 프로세스 안에서 여러 스레드가 존재할 수 있습니다.

이런 스레드 들은 하나의 프로세스 안에서 Code, Data Heap 영역을 공유하게 되고 각각 자신만의 stack영역을 갖게 됩니다.
따라서 스레드를 활용하면 다음과 같은 장점을 갖게 됩니다.
- 위에서 언급했듯 통신 비용이 프로세스 간 통신에 비해 훨씬 적게 듭니다.
- 시스템의 자원을 절약할 수 있습니다. (공유하고 있는 것이 있으니까...)
하지만 이로 인해 생기는 문제점 또한 있습니다. 스레드를 이용하면 데이터 관리가 까다롭습니다.
여러 스레드들은 하나의 프로세스에서 여러 영역을 공유하게 됩니다. java를 예로 들자면 특히 Heap 영역에 new 클래스() 해서 생긴 객체들을 공유합니다. 이때 두 스레드가 하나의 객체에 동시에 접근한다고 가정해 봅시다.
어떤 객체가 데이터 1을 가지고 있습니다.
스레드 1은 해당 객체에 데이터를 1 더해주려고 합니다.
스레드 2는 해당 객체에 데이터를 2 곱해주려고 합니다.
해당 작업이 순서대로 정상적으로 끝난다면 결과적으로 객체의 데이터는 4가 됩니다.

하지만 스레드는 다음과 같은 문제가 생길 수 있습니다.
- 스레드 1이 데이터 1인 객체에 접근한다.
- 스레드 1의 연산이 끝나기 전에 스레드 2가 객체에 접근한다. 데이터는 여전히 1이다.
- 스레드 1이 연산을 수행하면 데이터가 2가 된다. 스레드 2 또한 데이터가 1인 상태로 연산을 시작했기 때문에 데이터는 2가 된다.
방금 말한 것은 멀티 스레드를 사용함으로써 생길 수 있는 이슈의 예중 한 가지에 대해 간단하게 이야기 한 것 입니다.
사실 이 부분도 제대로 다루려면 글이 하나가 나올 것 같기 때문에 다음 기회에 더 자세하게 다뤄보도록 하겠습니다.
'CS > 운영체제' 카테고리의 다른 글
| 운영체제 - 교착상태(Deadlock)와 해결 방안 (0) | 2020.08.13 |
|---|---|
| 운영체제 - 상호배제의 기법, 세마포어 / 뮤텍스 / 모니터 (0) | 2020.08.07 |

